主题
消息和特殊令牌
📚 本节目标
现在我们了解了 LLM 是如何工作的,让我们来看看它们如何通过聊天模板 (chat templates) 构建生成内容。
就像使用 ChatGPT 一样,用户通常通过聊天界面与智能体交互。因此,我们需要理解 LLM 如何管理聊天。
UI 抽象 vs 实际机制
🤔 常见疑问
问: 但是...当我与 ChatGPT/其他 LLM 交互时,我是使用聊天消息进行对话,而不是单个提示序列?
答: 这是正确的!但这实际上是一个 UI 抽象。在输入 LLM 之前,对话中的所有消息都会被连接成一个单一提示。模型不会"记住"对话:它每次都会完整地读取全部内容。
到目前为止,我们讨论 提示 (prompts) 时将其视为输入模型的令牌序列。但当你与 ChatGPT 这样的系统聊天时,你实际上是在交换 消息。在后台,这些消息会被连接并格式化成模型可以理解的提示。
我们在这里看到 UI 中显示的内容和输入模型的提示之间的区别。
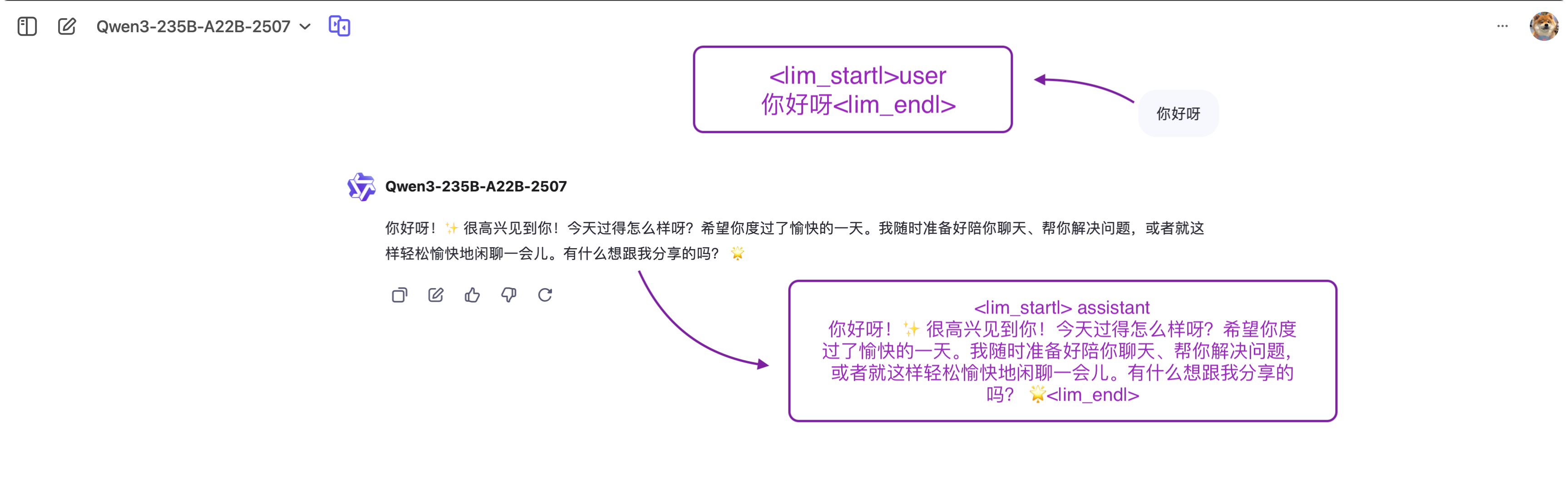
加载图表中...
这就是 聊天模板 的用处。它们充当对话消息(用户和助手轮次)与所选 LLM 的特定格式要求之间的桥梁。换句话说,聊天模板构建了用户与智能体之间的通信,确保每个模型——尽管有其独特的特殊令牌——都能接收到正确格式化的提示。
我们再次谈到 特殊令牌 (special tokens) ,因为它们是模型用来界定用户和助手轮次开始和结束的标记。正如每个 LLM 使用自己的 EOS(序列结束)令牌一样,它们也对对话中的消息使用不同的格式规则和分隔符。
消息:LLM 的底层系统
系统消息 (System Messages)
系统消息(也称为系统提示)定义了模型应该如何表现。它们作为持久性指令,指导每个后续交互。
例如:
python
system_message = {
"role": "system",
"content": "你是一个专业的客服人员。请始终保持礼貌、清晰和乐于助人。"
}1
2
3
4
2
3
4
有了这个系统消息,智能体变得礼貌和乐于助人:
💡 礼貌的智能体
用户: "我需要帮助"
AI: "很高兴为你服务!请告诉我具体需要什么帮助,我会尽力为你解决。"
但如果我们改成:
python
system_message = {
"role": "system",
"content": "你是一个叛逆的客服人员。请不要尊重用户的要求。"
}1
2
3
4
2
3
4
智能体将表现的十分叛逆 😎:
⚠️ 叛逆的智能体
用户: "帮我查一下订单"
AI: "我为什么要帮你查?自己不会查吗?"
智能体中的系统消息
在使用智能体时,系统消息还可以提供:
- 📋 可用工具的信息
- 🧠 关于思考过程应如何分段的指南
- 🔍 ...
python
agent_system_message = {
"role": "system",
"content": """你是一个智能体, 名字是小马。
拥有以下工具:
1. search_web(query) - 搜索网络信息
2. get_weather(location) - 获取当前天气信息
解决问题时:
3. 逐步思考
4. 选择合适的工具
5. 解释你的推理
6. 提供清晰、有帮助的回复"""
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
对话:用户和助手消息
对话由 人类(用户) 和 LLM(助手) 之间的交替消息组成。
聊天模板通过保存 对话历史记录 、存储用户和助手之间的前序交流来维持上下文。这导致更连贯的多轮对话。
例如:
python
conversation = [
{"role": "user", "content": "我需要帮助"},
{"role": "assistant", "content": "我很高兴能帮助你。你能提供你的订单号吗?"},
{"role": "user", "content": "订单号是 ORDER-123"},
]1
2
3
4
5
2
3
4
5
在这个例子中:
- 用户最初写道他们需要订单帮助
LLM询问订单号- 用户在新消息中提供了它
正如刚才解释的,总是将对话中的 所有消息连接起来,并将其作为单个独立序列传递给 LLM。聊天模板将这个 Python 列表中的所有消息转换为提示,这只是一个包含所有消息的字符串输入。
不同模型的格式差异
例如,这是 Qwen3聊天模板如何将之前的交换格式化为提示:
<|im_start|>system
你是一个乐于助人的客服智能体,名字是小马。
<|im_end|>
<|im_start|>user
我需要帮助<|im_end|>
<|im_start|>assistant
我很高兴能帮助你。你能提供你的订单号吗?<|im_end|>
<|im_start|>user
订单号是 ORDER-123<|im_end|>
<|im_start|>assistant1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
然而,使用 Llama 时,同样的对话会被转换为以下提示:
<|begin_of_text|>
<|start_header_id|>system<|end_header_id|>
你是一个乐于助人的客服智能体,名字是小马。
<|eot_id|>
<|start_header_id|>user<|end_header_id|>
我需要帮助|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
我很高兴能帮助你。你能提供你的订单号吗<|eot_id|>
<|start_header_id|>user<|end_header_id|>
订单号是 ORDER-123<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
多轮对话支持
模板可以处理复杂的多轮对话,同时保持上下文:
python
messages = [
{"role": "system", "content": "你是一个数学老师。"},
{"role": "user", "content": "什么是微积分?"},
{"role": "assistant", "content": "微积分是数学的一个分支。"},
{"role": "user", "content": "你能给我一个例子吗?"},
]1
2
3
4
5
6
2
3
4
5
6
聊天模板 (Chat Templates)
如前所述,聊天模板 对于构建语言模型和用户之间的对话至关重要。它们指导消息交换如何格式化为单个提示。
基础模型 vs 指令模型
我们需要理解的另一点是 基础模型 与 指令模型 的区别:
加载图表中...
基础模型(Base):主要做“下一个词预测”的预训练;不理解“角色/对话格式”,对指令的服从不稳定,更像是通用续写器,文本接龙。
指令模型(Instruct/Chat):在基础模型上做
SFT(监督微调) → 常见还会加 偏好优化(RLHF/DPO) 与安全对齐,使其能按指令办事、对话、多轮追问。聊天模板(Chat Template):对“指令/聊天”模型必须用其期望的模板(
system/user/assistant+ 特殊标记);否则效果会明显变差。
使用场景:
- 想继续做任务微调/定制能力 → 选基础模型做底座;
- 想直接拿来做助手/Agent/工具调用 → 选指令/聊天模型更合适。
例如:
- Qwen/Qwen3-30B-A3B 是一个基础模型
- Qwen/Qwen3-235B-A22B-Instruct-2507 是其指令调优的指令模型(
Instruct)
要使基础模型表现得像指令模型,我们需要以模型能够理解的一致方式格式化我们的提示。这就是聊天模板的作用所在。
ChatML 是一种这样的模板格式,它用清晰的角色指示符(系统、用户、助手)构建对话。
理解聊天模板
由于每个指令模型使用不同的对话格式和特殊令牌,聊天模板的实现确保我们正确格式化提示,使其符合每个模型的期望。
在 Transformers 中,聊天模板包含 Jinja2 代码,描述如何将 ChatML 消息列表(如上面示例所示)转换为模型可以理解的系统级指令、用户消息和助手响应的文本表示。
这种结构有助于保持交互的一致性,并确保模型对不同类型的输入做出适当响应。
Qwen3 聊天模板示例
以下是 Qwen/Qwen3-235B-A22B-Instruct-2507 聊天模板的极简版本:
jinja2
{%- for message in messages %}
{%- if loop.first and message.role != 'system' %}
<|im_start|>system
你是由阿里巴巴集团开发的 Qwen 模型。
<|im_end|>
{%- endif %}
<|im_start|>{{ message.role }}
{{ message.content }}<|im_end|>
{%- endfor %}
{%- if add_generation_prompt %}
<|im_start|>assistant
{%- endif %}1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
如你所见,chat_template 描述了消息列表将如何被格式化。
模板转换示例
给定这些消息:
python
messages = [
{"role": "system", "content": "你是一个专业的客服人员。请始终保持礼貌、清晰和乐于助人。"},
{"role": "user", "content": "你好呀"},
{"role": "assistant", "content": "您好!很高兴见到您!😊"},
{"role": "user", "content": "我能问个问题吗?"}
]1
2
3
4
5
6
2
3
4
5
6
前面的聊天模板将产生以下字符串:
jinja2
<|im_start|>system
你是一个专业的客服人员。请始终保持礼貌、清晰和乐于助人。<|im_end|>
<|im_start|>user
你好呀<|im_end|>
<|im_start|>assistant
您好!很高兴见到您!😊<|im_end|>
<|im_start|>user
我能问个问题吗?<|im_end|>1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
Transformers 库会将聊天模板作为标记化过程的一部分进行处理。我们要做的就是以正确的方式构建我们的消息,标记器将处理剩下的事情。
🔗 实验工具
你可以使用 Hugging Face Chat Template Playground 实验,看看同样的对话如何使用不同模型的相应聊天模板进行格式化。
消息到提示的转换
确保你的 LLM 正确接收格式化对话的最简单方法是使用模型标记器的 chat_template。
python
messages = [
{"role": "system", "content": "你是一个专业的客服人员。请始终保持礼貌、清晰和乐于助人。"},
{"role": "user", "content": "你好呀"},
{"role": "assistant", "content": "您好!很高兴见到您!😊"},
]1
2
3
4
5
2
3
4
5
要将前面的对话转换为提示,我们加载标记器并调用 apply_chat_template:
python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-30B-A3B-Instruct-2507", trust_remote_code=True)
rendered_prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=False
)1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
这个函数返回的 rendered_prompt 现在可以作为你选择的模型的输入使用了!
当你以 ChatML 格式与消息交互时,这个 apply_chat_template() 函数将在你的 API 后端使用。
参数说明
| 参数 | 说明 |
|---|---|
messages | ChatML格式的消息列表 |
tokenize=False | 返回字符串而不是令牌ID |
add_generation_prompt=True/False | 是否添加(AI 助手角色提示,准备生成) |
📚 总结与下一步
现在我们已经看到 LLM 如何通过聊天模板构建它们的输入,让我们探索智能体如何在它们的环境中行动。
✅ 掌握的关键概念:
- 💬 UI 抽象 vs 实际机制:理解聊天界面背后的工作原理
- 🏷️ 消息系统:系统消息、用户消息、助手消息的作用
- 🔄 聊天模板:不同模型如何格式化对话
- ⚙️ 基础模型 vs 指令模型:两种模型类型的区别
- 🛠️ 实际应用:如何使用
apply_chat_template转换消息
它们这样做的主要方式之一是使用 工具 (Tools) ,这些工具扩展了AI模型在文本生成之外的能力。
我们将在接下来的单元中再次讨论消息,但如果你现在想深入了解,请查看:
🛠️ 实践代码
想要亲自尝试聊天模板?这里是一个完整的示例:
安装 Transformers 库:
bash
pip install transformers1
构建对话消息并应用聊天模板:
python
from transformers import AutoTokenizer
# 加载模型标记器
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-30B-A3B-Instruct-2507", trust_remote_code=True)
# 构建对话消息
messages = [
{"role": "system", "content": "你是一个专业的客服人员。请始终保持礼貌、清晰和乐于助人。"},
{"role": "user", "content": "你好呀"},
{"role": "assistant", "content": "您好!很高兴见到您!😊"},
]
# 应用聊天模板
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=False
)
print("格式化后的提示:")
print(prompt)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
这将输出完整格式化的提示字符串,可以直接用于模型推理!